I don’t know but the suggest makes me so happy.
- 0 Posts
- 15 Comments
Joined 1 year ago
Cake day: June 11th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 2·3 months ago
2·3 months agoTry your local library.
I think it was the EPA’s National Compute Center. I’m guessing based on location though.
When I was in highschool we toured the local EPA office. They had the most data I’ve ever seen accessible in person. Im going to guess how much.
It was a dome with a robot arm that spun around and grabbed tapes. It was 2000 so I’m guessing 100gb per tape. But my memory on the shape of the tapes isn’t good.
Looks like tapes were four inches tall. Let’s found up to six inches for housing and easier math. The dome was taller than me. Let’s go with 14 shelves.
Let’s guess a six foot shelf diameter. So, like 20 feet circumference. Tapes were maybe .8 inches a pop. With space between for robot fingers and stuff, let’s guess 240 tapes per shelf.
That comes out to about 300 terabytes. Oh. That isn’t that much these days. I mean, it’s a lot. But these days you could easily get that in spinning disks. No robot arm seek time. But with modern hardware it’d be 60 petabytes.
I’m not sure how you’d transfer it these days. A truck, presumably. But you’d probably want to transfer a copy rather than disassemble it. That sounds slow too.
Not looking at the man page, but I expect you can limit it if you want and the parser for the parameter knows about these names. If it were me it’d be one parser for byte size values and it’d work for chunk size and limit and sync interval and whatever else dd does.
Also probably limited by the size of the number tracking. I think dd reports the number of bytes copied at the end even in unlimited mode.
 10·3 months ago
10·3 months agoMine looks a little like that. It’s my job though. Everything’s on GitHub.
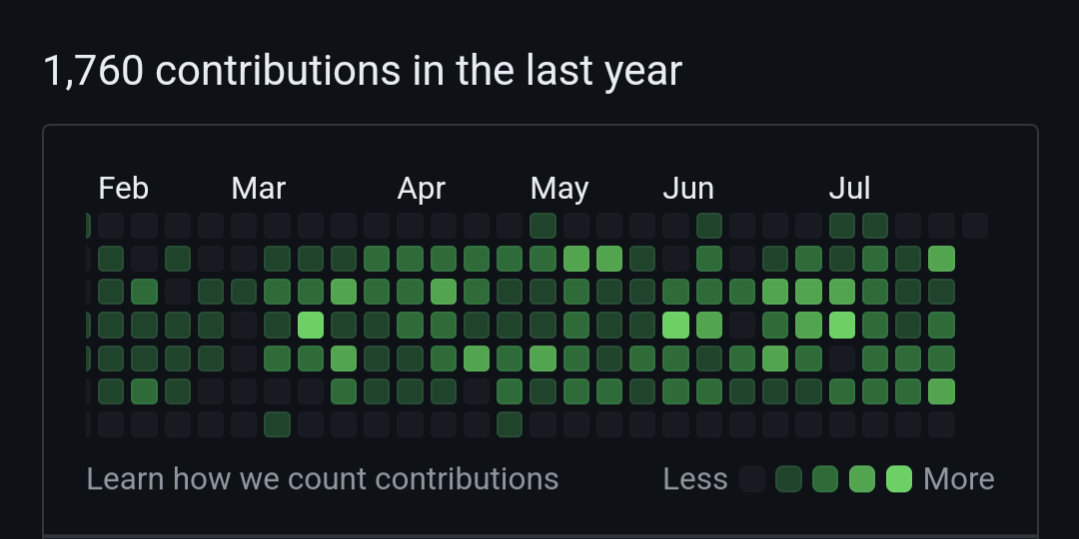
I’m with you. Words change.
There are still good southerners. But it’s hard sometimes. I still live here but I’m weary for my kids. It’s fine for now.
I wish you peace with your family. Whatever that means.
Windows -> RedHat -> Windows -> Gentoo -> Ubuntu -> RHEL -> Ubuntu -> Debian -> Arch


We squash. I’m not really interesting in your local journey to land the change. It’s sometimes useful during review, but after that it’s mostly the state of the main branch I care about. It’s what I need to bisect anyway.
I don’t like commits that are just references to issues. Copy the issue into the commit message so
git blametells you something useful. Unless it’s just closing a simple big. Then the title and issue reference are plenty.Depends on the project I imagine.
I wonder what my last commit at each job was. I’ll bet it was boring. About 10% of my commit messages are genuinely interesting.
I think the last new instruction the JVM added was invokedynamic like 10 years ago. I believe they did it so lambdas could be called efficiently. Polymorphic incline cache and stuff.
But the JVM has grown more complex in other ways. The way to force simd instructions is pretty wild, for example.
I don’t know enough to call it a mess or not. It works though.
That’s why I hate Ferris wheels. Every time.
Although it was his first day in charge, Sliney had an over-25-year background in air traffic and management in the FAA.
I recommend it. Try to go in blind.